索引是一种用来在某中条件下加速查询的结构。考虑如下查询:
1 | SELECT * FROM FOODS WHERE NAME='苹果'; |
当数据库搜索匹配的行时,执行这种查询的默认方法是调用顺序扫描。也就是说,逐个搜索(扫描)表中的所有行,查看 NAME 属性是否匹配 “苹果”。
但是,如果频繁使用这种查询,并且表 FOODS 非常大,使用索引的方法查找数据就更有意义了。与其他许多数据库类似,SQLite 使用 B-tree 做索引。
索引也会增加数据库的大小。从字面上理解,它们复制了一份索引的字段。如果表中的所有字段都创建索引,表的大小可能翻倍。另一个要考虑的情况是索引的维护。进行 insert、update 和 delete 操作时,除了修改表,数据库也必须修改对应的索引。虽然索引可以加速查询,但是它们可能降低 insert、update 和类似操作的速度。创建索引的命令如下:
1 | create index [unique] index_name on table_name (columns) |
变量 index_name 是索引的名称,table_name 是包括索引所在字段的表名称,变量 colums 是一个字段或以逗号分隔的多个字段。
如果使用关键字 unique,将会在索引上添加约束,索引中的所有值必须是唯一的。这不仅适用于索引,也适用于索引所在字段。unique 关键字覆盖 index 中的所有字段,不管是联合值还是单个值,都必须是唯一的。例如:
1 | CREATE TABLE ACCOUNT(NAME TEXT, PASS TEXT); |
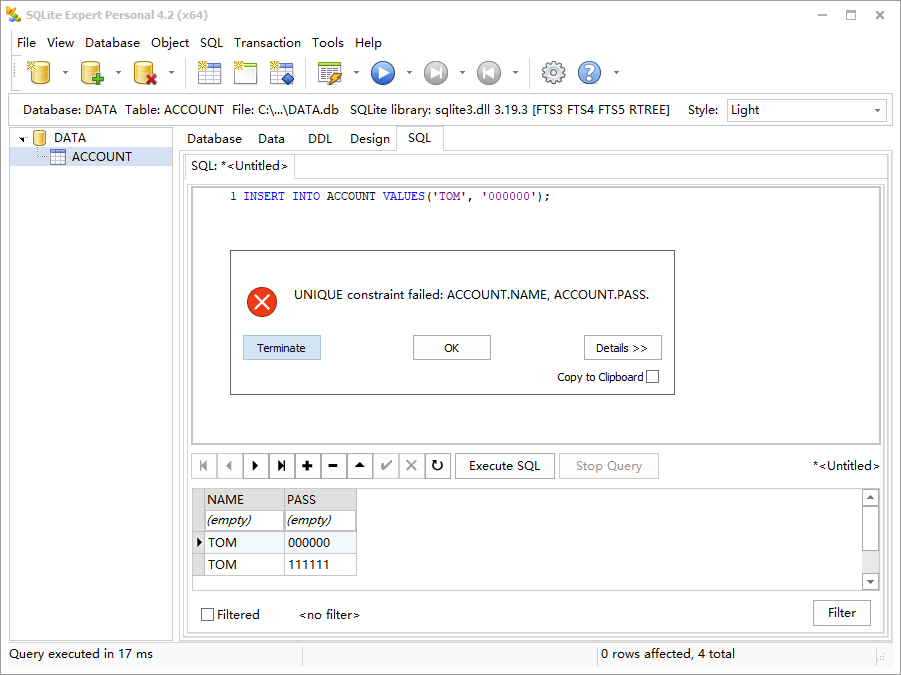
可以看到,唯一性约束不仅存在于单个字段,也存在于联合字段。注意,排序规则在这发挥了重要作用。若要删除索引,可使用 drop index 命令,该命令定义如下:
1 | drop index index_name; |
排序规则
索引中的每个字段都有相关的排序规则,例如,要在 ACCOUNT.NAME 上创建大小写不敏感的索引,可以使用如下命令:
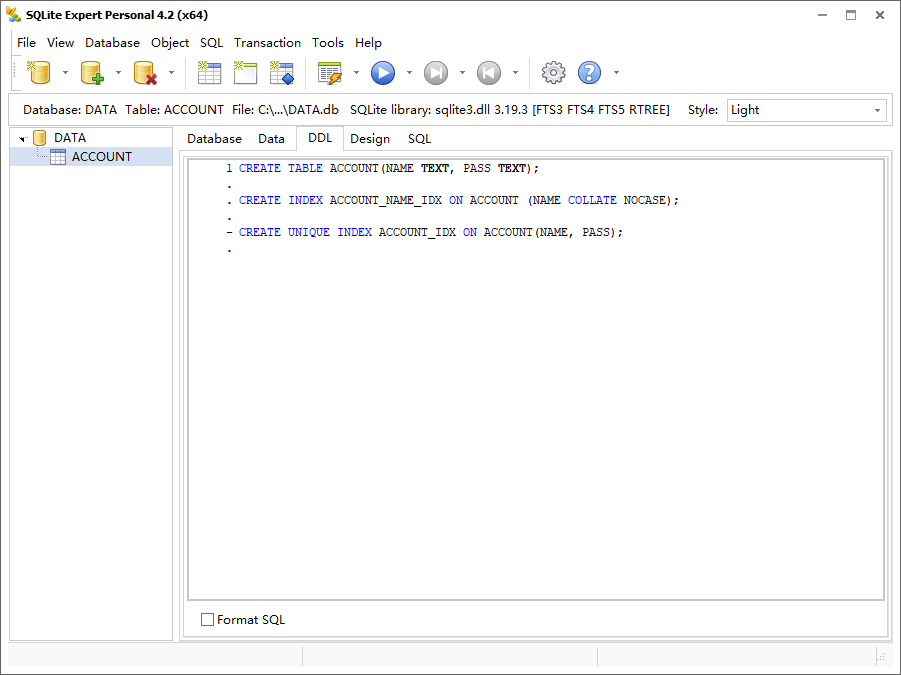
1 | CREATE INDEX ACCOUNT_NAME_IDX ON ACCOUNT (NAME COLLATE NOCASE); |
这意味着 NAME 字段的值将按照大小写无关进行排序。可以切换到 DDL 视图查看表中的索引信息。
使用索引
了解何时使用索引以及何时不用索引是非常重要的。SQLite 中有一些具体的条件来判断是否使用索引。如果可以的话,对于下面会在 where 子句中出现的表达式,SQLite 将使用单个字段索引。
1 | column {=|>|>=|<=|<} expression |
在使用之前,多字段索引有更复杂的条件。下面通过例子可以更好地说明,假设有如下表定义:
1 | CREATE TABLE FOO (A, B, C, D); |
此外,创建如下多字段索引:
1 | CREATE INDEX FOO_IDX ON FOO (A, B, C, D); |
FOO_IDX 字段的顺序是从左到右的。也就是说,在如下查询中:
1 | SELECT * FROM FOO WHERE A=1 AND B=2 AND D=3; |
只有第一个和第二个条件将使用索引。不使用第三个条件的原因是没有条件使用 C 去缩小到 D 的差距。基本上,当 SQLite 使用多字段索引时,它从左到右智能地使用字段,即从左边的字段开始,查询使用字段的条件,然后移动到第二个字段,以此类推,一直继续,直到 where 子句中无法找出有效条件。
1 | SELECT * FROM FOO WHERE A>1 AND B=2 AND C=3 AND D=4; |
SQLite 会在字段 A 上执行索引扫描,表达式 A>1 称为最右边的索引字段,因为它使用了不等于号。之后的所有字段作为结果是不合格的。类似地,如下语句使用索引字段 A 和 B,在 B>2 处停止,因为它是最右的不等号索引字段。
1 | SELECT * FROM FOO WHERE A=1 AND B>2 AND C=3 AND D=4; |
最后,创建索引时,一定要有理由确保可以获得性能的改善。选择好的索引是非常重要的:分布凌乱的索引可能会导致希望获得良好性能的愿望落空。