数据库管理一般用于控制数据库如何操作。要执行的许多数据库管理任务都可以通过 SQL 命令完成。SQLite 包括自己一些独特的管理功能,如将多个数据库附加“attach”到一个连接上,以及用来设置各种配置参数的数据库编译指示(pragma)。
一、附加数据库
SQLite 允许你用 attach 命令将多个数据库“附加”到当前连接上。当你附加了一个数据库时,它的所有内容在当前数据库文件的全局范围内都是可存取的。attach 的语法如下:
1 | attach [database] filename as database_name; |
其中,filename 指 SQLite 数据库的文件名称和路径,database_name 指要引用的数据库和对象的逻辑名称。主数据库自动赋名为 main。如果创建任何临时的对象,SQLite 会创建一个附加的数据库,并命名为 temp(可以使用后面描述的编辑指示 database_list 查看这些对象)。逻辑名称可以用来引用附加数据库内的对象,与此同时,引用附加数据库内的对象必须提供逻辑名。例如,如果两个数据库都有名为 FOODS 的表,附加数据库的逻辑名为 DATA2,查询 DATA2 中 FOODS 表的唯一方式是使用全限定名 DATA2.FOODS,例如:
TEST 数据库文件路径为:C:\Users\sunzn\Desktop\TEST.db,该数据库下包含一个 FOODS 表,建表语句如下:
1 | CREATE TABLE FOODS(ID INTEGER PRIMARY KEY, NAME TEXT); |
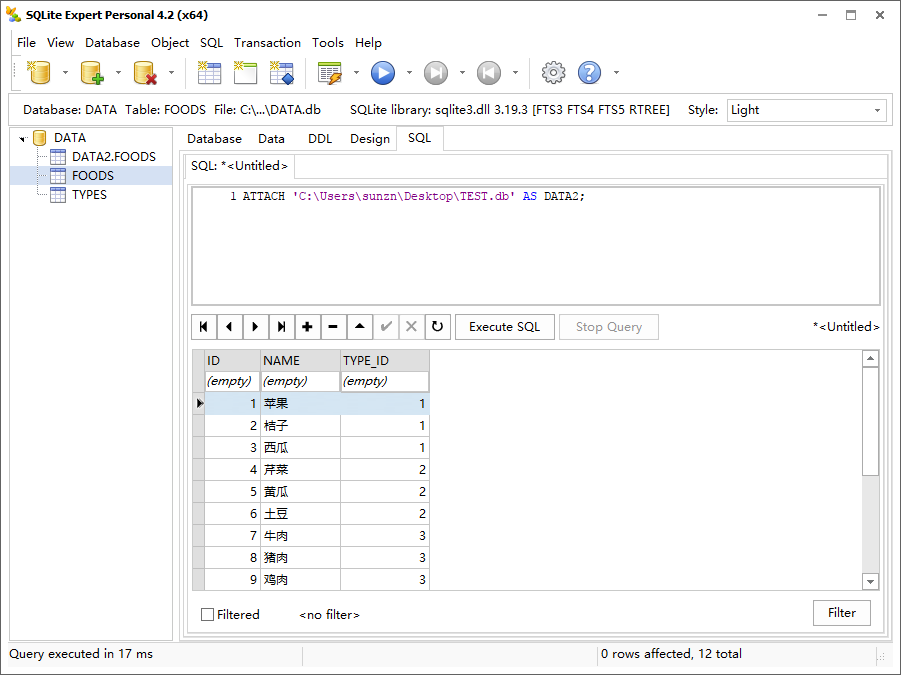
这时,关闭数据库 TEST,将 TEST 数据库附加到 DATA 数据库,逻辑名赋值为 DATA2。
1 | ATTACH 'C:\Users\sunzn\Desktop\TEST.db' AS DATA2; |
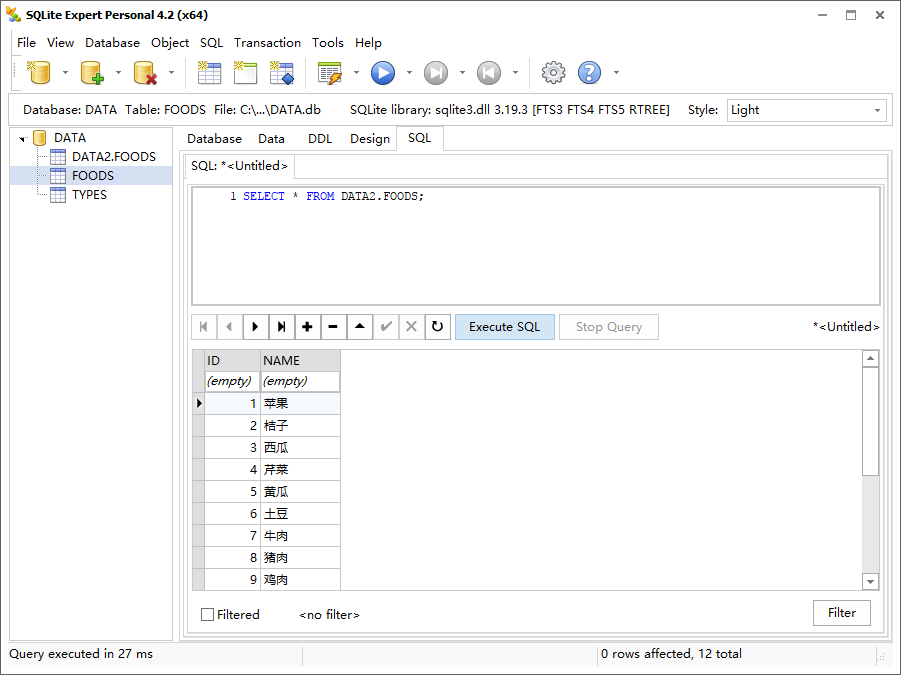
然后查询附加的 DATA2.FOODS 表,结果如下。
1 | SELECT * FROM DATA2.FOODS; |
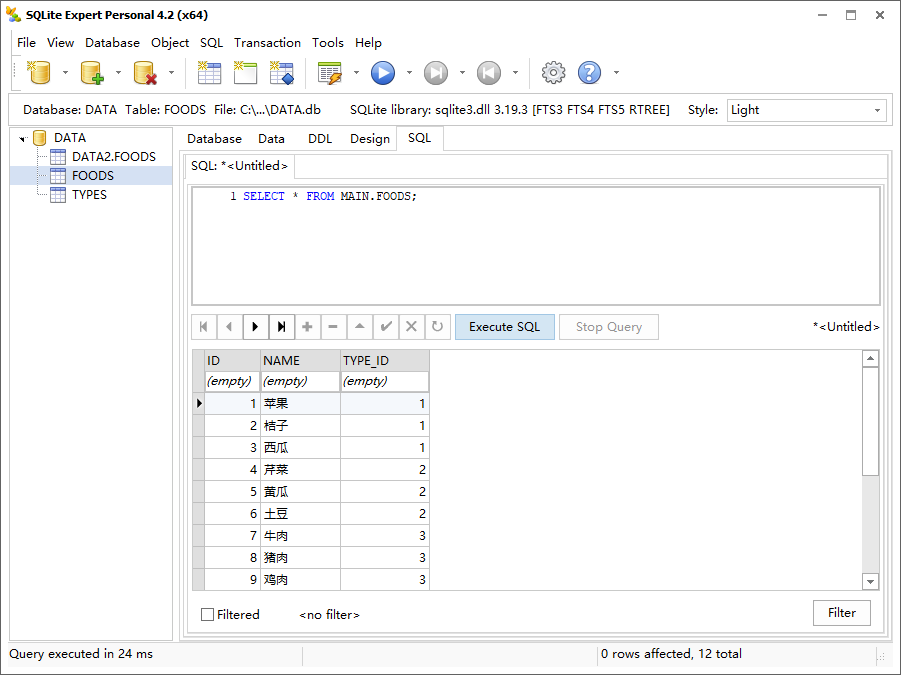
如果要查询主数据库中的表,需要指定逻辑名 MAIN,因为当有数据库附加的时候,主数据库会自动赋名为 MAIN。
1 | SELECT * FROM MAIN.FOODS; |
临时表也可以这样引用:
1 | CREATE TEMP TABLE FOO AS SELECT * FROM TYPES LIMIT 3; |

可以使用 detach databse 命令将数据库分离,定义如下:
1 | detach [database] database_name; |
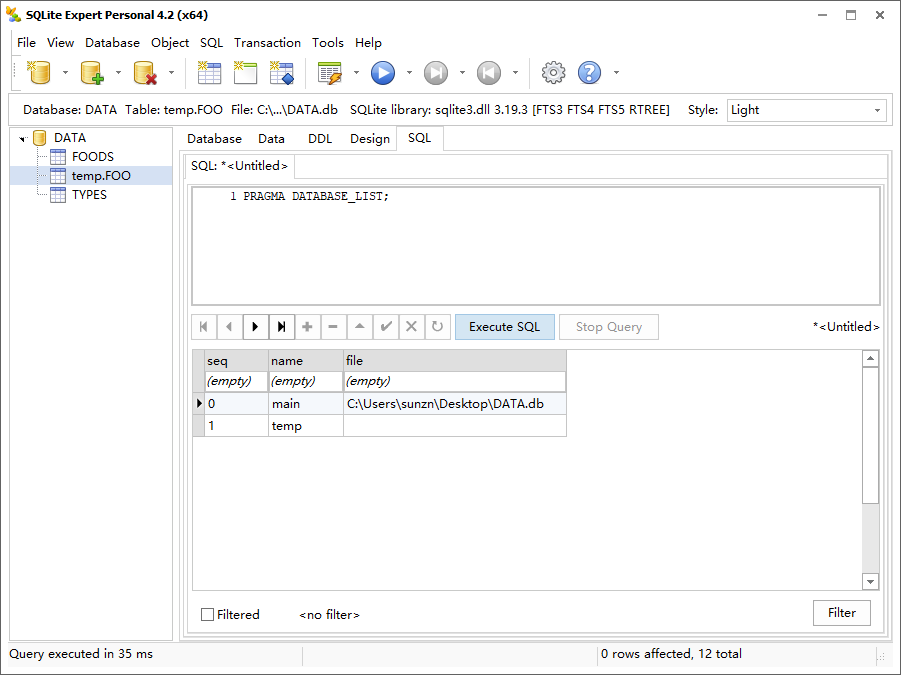
该命令使用附加数据库(就是 database_name)的逻辑名作为参数,分离相关的数据库文件。可以使用 database_list 编译指示获取附加的数据库列表,相关内容在“数据库配置”一节有解释。
二、数据库清理
SQLite 有两个命令用于清理数据库—— reindex 和 vacuum。reindex 用于重建索引,它有如下两种形式:
1 | reindex collation_name; |
第一种形式重建所有使用指定排序名称(collation_name)的索引。当要改变用户定义的排序行为(例如中文中的多排序顺序)时才需要这种形式。要重构表中的所有索引(或指定名称的索引),可以使用第二种形式的命令。
vacuum 通过重构数据库文件清理那些未使用的空间。如果存在处于开放状态的事务,vacuum 不会执行。一种代替手动运行 vacuum 的方法是使用 autovacuum。该功能可以通过使用 auto_vacuum 编译指示启用,下一节将会有说明。
三、数据库配置
SQLite 没有配置文件,它的所有配置参数都是用编译指示(pragma)来实现的。编译指示以独特的方式工作,有时像变量,有时像命令。它们涵盖了数据库的大部分参数,例如运行信息、数据库 schema、版本、文件格式、内存使用和调用。一些编译指示是可读的,像变量一样设置,一些要求有参数,像函数那样调用。许多编译指示既有临时形式,也有永久形式。临时形式的设置仅仅在生命周期内影响当前会话。永久设置存储在数据库中影响所有的会话。缓冲区的大小就是这样的设置。
连接缓冲区大小
缓冲区尺寸的编译指示控制一个连接可以在内存中使用多少个数据库页。要设置当前缓冲区大小的默认值,可以按照如下方式执行:
1 | pragma cache_size; |
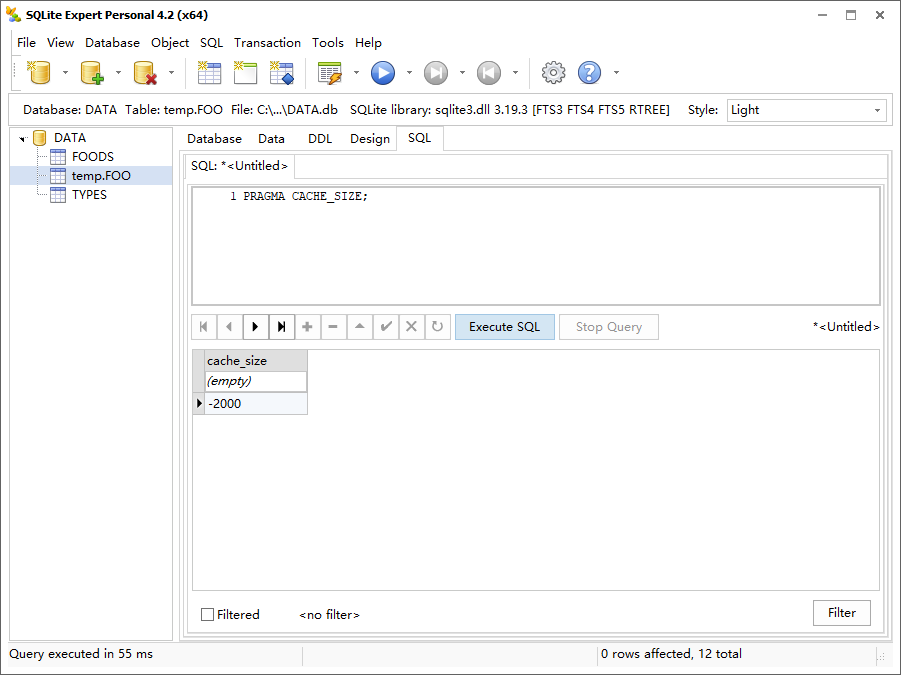
1 | pragma cache_size=10000; |

使用 default_cache_size 编译指示可以为所有的连接设置永久缓冲区的大小。这种设置可以存储在数据库中,且只对之后的连接生效,当前连接不受影响。
缓冲区的一种用途是当连接处于预留状态(有预留锁)时,存储那些特定的变化。正如之前“事务”中所描述的,如果连接填满了缓冲区,它将无法继续进一步修改,直到获得排它锁,这也就意味着它可能必须等待其他读操作来清理。
如果程序对正在被许多连接使用的数据库执行很多的更新或删除操作,这将有助于增加缓冲区的大小。缓冲区越大,连接在获取排它锁之前能做的修改就越多。这样连接不仅在必须等待前可以做更多的工作,也减少了持有排它锁的时间,因为所有的工作在之前都做完了。这种情况下,持有排它锁的时间只需要足以将缓冲区的内容刷新到磁盘就可以。
获得数据库信息
使用数据库的 schema 编译指示可以获得数据库信息,定义如下:
| 命令 | 说明 |
|---|---|
| database_list | 列出所有附着的数据库 |
| index_info | 列出索引内字段的相关信息,索引名作为参数 |
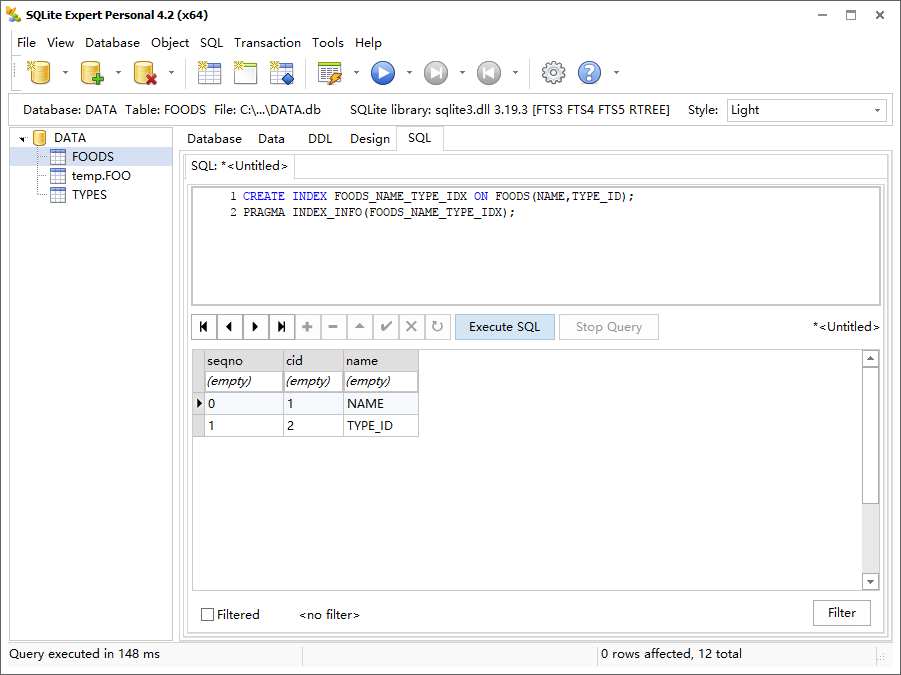
| index_list | 列出表中的索引信息,表明作为参数 |
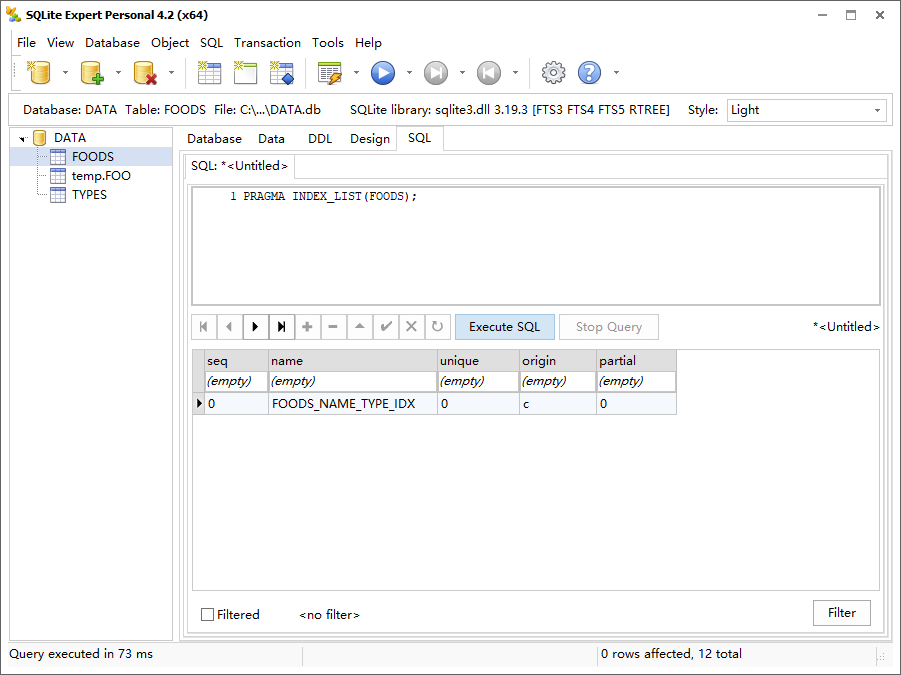
| table_info | 列出表中所有字段的相关信息 |
1 | CREATE INDEX FOODS_NAME_TYPE_IDX ON FOODS(NAME,TYPE_ID); |
1 | PRAGMA INDEX_LIST(FOODS); |
1 | PRAGMA TABLE_INFO(FOODS); |
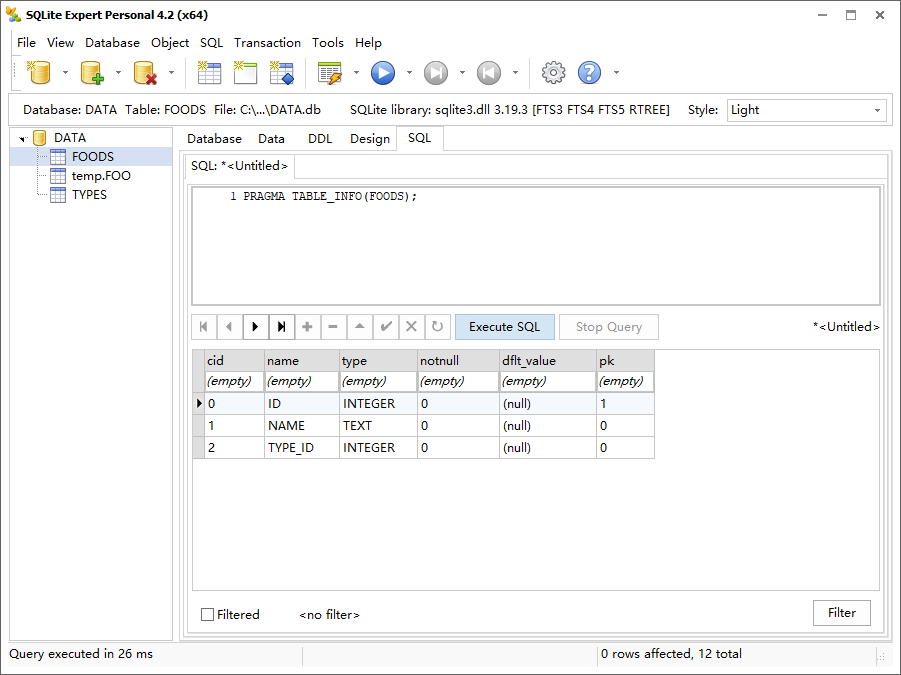
写同步
通常情况下,SQLite 会在关键时刻将所有的变化提交到磁盘以确保事务的持久性。这与其他数据库中的检查点功能类似。但是,考虑到性能因素,可以关闭这一功能,可以通过编译指示 synchronous 来实现。该编译指示有三种设置:full、normal 和 off。各自定义如下:
full:SQLite 在继续前,在关键点暂停以确保所有的数据都实际写入磁盘。这样确保了即使操作系统奔溃或电力中断,在重启后数据库依然是未损毁的。full 同步是非常安全的,但也较慢。
normal:SQLite 会在绝大多数关键点暂停,但是没有 full 模式频繁。normal 模式中某个凑巧的时刻电力中断可能会导致数据库损毁的情况发生,虽然这种概率非常小。实际中,很有可能遭受严重的磁盘操作失败或者其他不可恢复的硬件故障。
off:SQLite 将数据抛给操作系统后立即继续操作。这样可以加速一些操作,可加速高达 50 倍。如果运行 SQLite 的应用程序奔溃,数据依然是安全的。然而,如果操作系统奔溃或者计算机断电,数据库可能会损毁。
临时存储器
临时存储器就是 SQLite 保存临时性数据,例如临时表、索引和其他对象的地方。在默认情况下,SQLite 使用内编译的位置,这个位置根据平台的不同而有所变化。有两个编译指示控制临时存储器:temp_store 和 temp_store_directory。第一个编译指示决定 SQLite 是使用内存还是磁盘作为临时存储器。实际上有三个可能选项:default、file 和 memory。其中,default 选项使用内编译的默认项,file 选项使用操作系统文件,memory 选项使用内存。如果将 file 设置为存储介质,那么第二个编译指示 temp_store_directory 就是存储临时文件的目录。
页大小、编码和自动清理
数据库页大小、编码和自动清理必须在创建数据库前设置。也就是说,要修改默认设置,在新数据库中创建任何新对象前都必须设置这些编译指示。默认设置继承自主机的参数,例如磁盘扇区大小、UTF-8 编码。SQLite 支持的页大小范围是 512 字节到 32786 字节,即 2 的幂次。支持的编码有 UTF-8、UTF-16le(小字节头)、UTF-16be(大字节头)。
数据库的大小可以通过编译指示 auto_vacuum 自动保持在最小值。通常情况下,从数据库删除数据的事务提交时,数据库的大小不变。启用 auto_vacuum 时,当删除数据的事务提交时,数据库文件会缩小。为了支持这种功能,数据库内部需要存储额外的信息,这将导致数据库文件比不启用 auto_vacuum 的稍微大一些。vacuum 命令对那些使用 auto_vacuum 的数据库不起作用。
调试
有四个调试的编译指示。integrity_check 编译指示可以查看次序颠倒的记录、缺失页面、畸形记录以及损毁的索引。如果发现任何问题,返回一个描述问题的字符串。如果一切有序且正常,SQLite 返回 OK。其他编译指示可以用来追踪解析器和虚拟数据库引擎,只要数据库编译时启用了调试信息,就可以启用这些编译指示。
四、系统目录
sqlite_master 表是系统表,它包含数据库中所有表、视图、索引和触发器的信息。例如,DATA 数据库的当前内容如下:
1 | SELECT TYPE, NAME, ROOTPAGE FROM SQLITE_MASTER; |
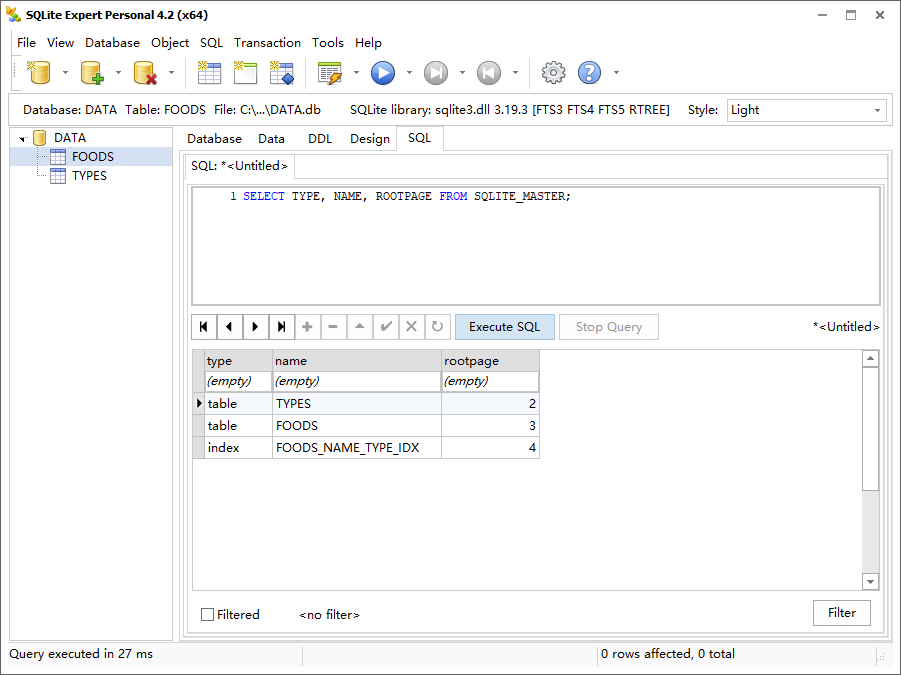
type 字段说明对象的类型,name 字段就是对象的名称,rootpage 指对象的第一个 B-tree 页面在数据库文件中的位置。后面的字段只与表和索引有关。
sqlite_master 表还包含称为 SQL 的字段,该字段用来存储创建对象的 DDL。例如:
1 | SELECT SQL FROM SQLITE_MASTER WHERE NAME='FOODS_NAME_TYPE_IDX'; |
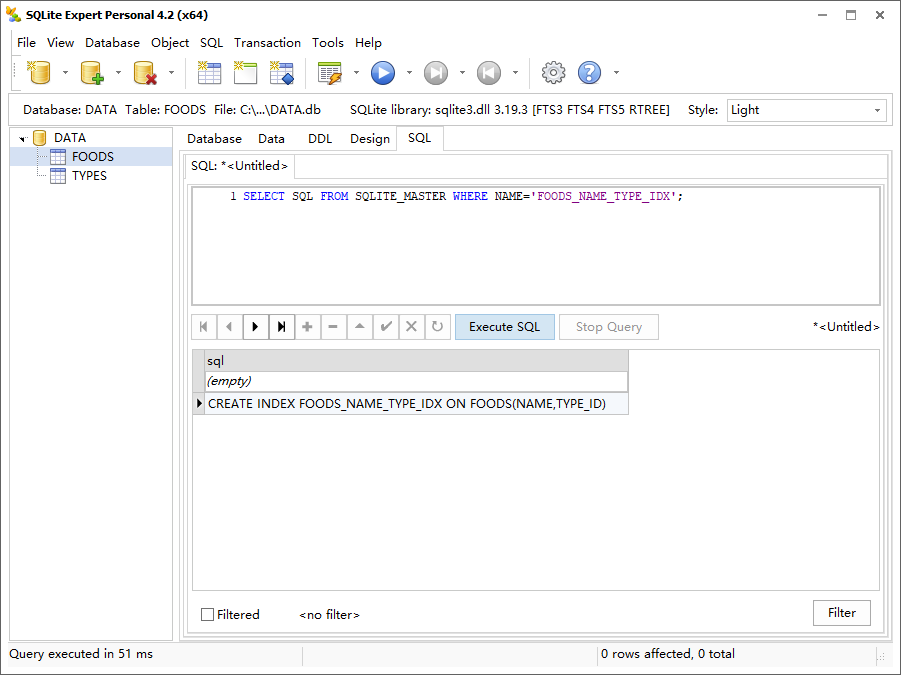
五、查看查询计划
可以使用 explain query plan 命令查看 SQLite 执行查询的方法。explain query plan 命令列出 SQLite 执行查询时访问处理表与数据的具体步骤。
使用 explain query plan 命令时,只需在该命令后面加上正常的查询文本。例如,下面的例子说明 explain query plan 给出的如何在 FOODS 表中执行查询。
1 | EXPLAIN QUERY PLAN SELECT * FROM FOODS WHERE ID = 1; |
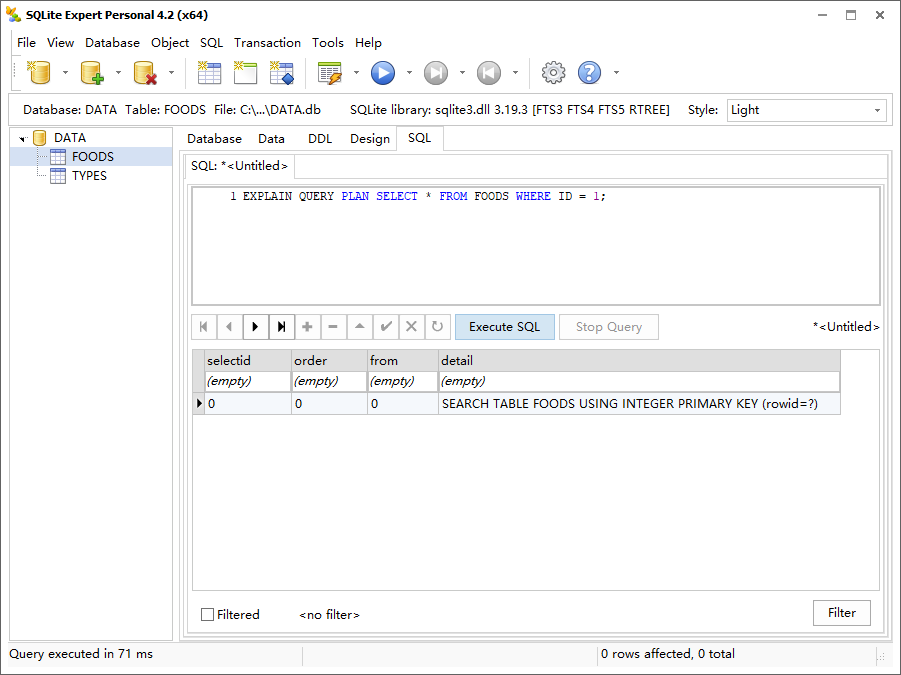
这意味着 SQLite 正在访问表 FOODS,使用主键(ID)执行访问(不是蛮力式的扫描表里的数据)。
研究这些查询计划是理解 SQLite 如何访问数据并满足查询的关键。你可以看到哪些地方何时、如何使用索引,以及表连接时的顺序。这对于解决那些运行时间很长的查询以及其他文件的作用是巨大的。